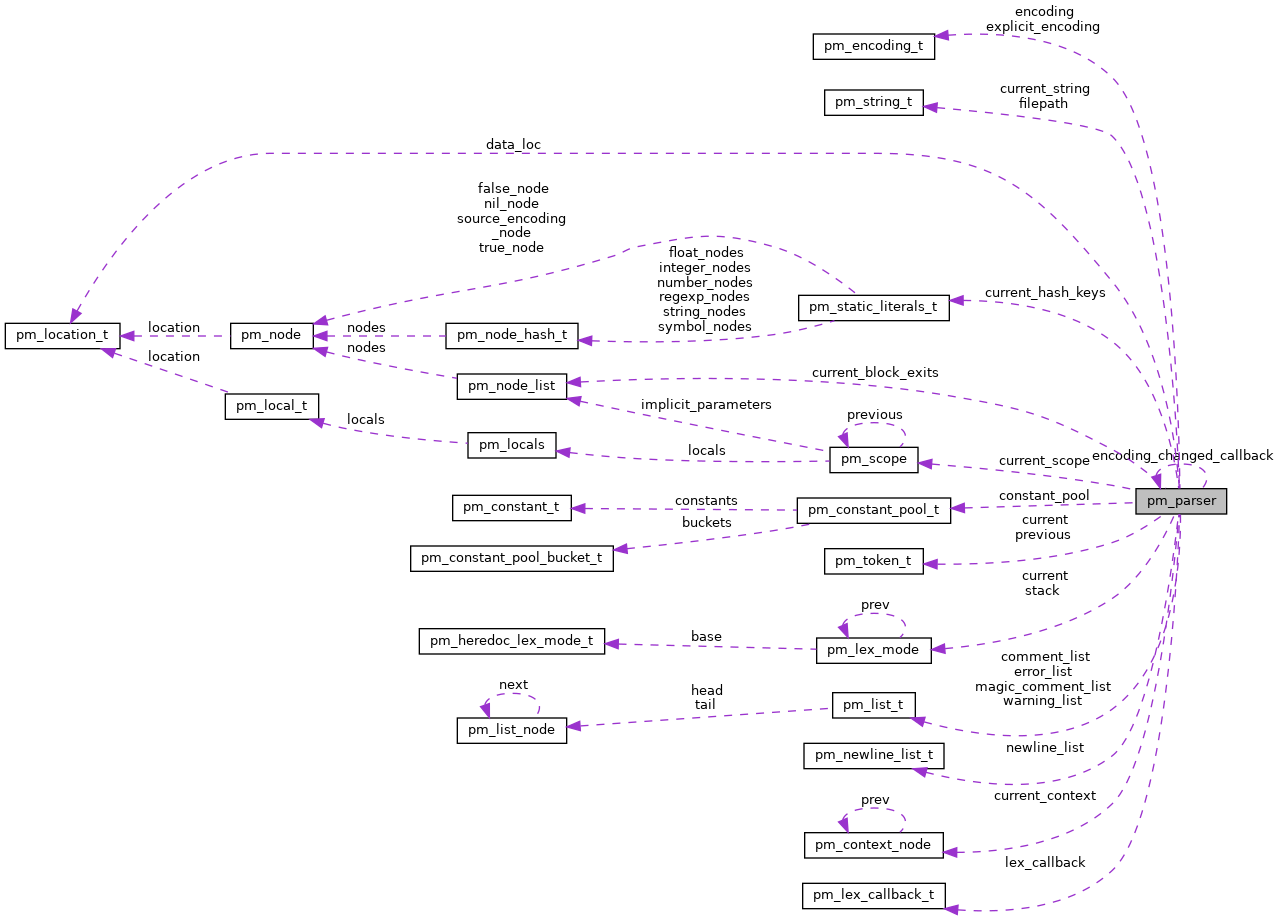
This struct represents the overall parser. More...
#include <parser.h>
Public Member Functions | |
| PRISM_EXPORTED_FUNCTION void | pm_parser_init (pm_arena_t *arena, pm_parser_t *parser, const uint8_t *source, size_t size, const pm_options_t *options) |
| Initialize a parser with the given start and end pointers. | |
| PRISM_EXPORTED_FUNCTION void | pm_parser_register_encoding_changed_callback (pm_parser_t *parser, pm_encoding_changed_callback_t callback) |
| Register a callback that will be called whenever prism changes the encoding it is using to parse based on the magic comment. | |
| PRISM_EXPORTED_FUNCTION void | pm_parser_free (pm_parser_t *parser) |
| Free any memory associated with the given parser. | |
| PRISM_EXPORTED_FUNCTION pm_node_t * | pm_parse (pm_parser_t *parser) |
| Initiate the parser with the given parser. | |
| PRISM_EXPORTED_FUNCTION pm_node_t * | pm_parse_stream (pm_arena_t *arena, pm_parser_t *parser, pm_buffer_t *buffer, void *stream, pm_parse_stream_fgets_t *stream_fgets, pm_parse_stream_feof_t *stream_feof, const pm_options_t *options) |
| Parse a stream of Ruby source and return the tree. | |
Data Fields | ||
| pm_arena_t * | arena | |
| The arena used for all AST-lifetime allocations. | ||
| uint32_t | node_id | |
| The next node identifier that will be assigned. | ||
| pm_lex_state_t | lex_state | |
| The current state of the lexer. | ||
| int | enclosure_nesting | |
| Tracks the current nesting of (), [], and {}. | ||
| int | lambda_enclosure_nesting | |
| Used to temporarily track the nesting of enclosures to determine if a { is the beginning of a lambda following the parameters of a lambda. | ||
| int | brace_nesting | |
| Used to track the nesting of braces to ensure we get the correct value when we are interpolating blocks with braces. | ||
| pm_state_stack_t | do_loop_stack | |
| The stack used to determine if a do keyword belongs to the predicate of a while, until, or for loop. | ||
| pm_state_stack_t | accepts_block_stack | |
| The stack used to determine if a do keyword belongs to the beginning of a block. | ||
| struct { | ||
| pm_lex_mode_t * current | ||
| The current mode of the lexer. | ||
| pm_lex_mode_t stack [PM_LEX_STACK_SIZE] | ||
| The stack of lexer modes. | ||
| size_t index | ||
| The current index into the lexer mode stack. | ||
| } | lex_modes | |
| A stack of lex modes. | ||
| const uint8_t * | start | |
| The pointer to the start of the source. | ||
| const uint8_t * | end | |
| The pointer to the end of the source. | ||
| pm_token_t | previous | |
| The previous token we were considering. | ||
| pm_token_t | current | |
| The current token we're considering. | ||
| const uint8_t * | next_start | |
| This is a special field set on the parser when we need the parser to jump to a specific location when lexing the next token, as opposed to just using the end of the previous token. | ||
| const uint8_t * | heredoc_end | |
| This field indicates the end of a heredoc whose identifier was found on the current line. | ||
| pm_list_t | comment_list | |
| The list of comments that have been found while parsing. | ||
| pm_list_t | magic_comment_list | |
| The list of magic comments that have been found while parsing. | ||
| pm_location_t | data_loc | |
| An optional location that represents the location of the END marker and the rest of the content of the file. | ||
| pm_list_t | warning_list | |
| The list of warnings that have been found while parsing. | ||
| pm_list_t | error_list | |
| The list of errors that have been found while parsing. | ||
| pm_scope_t * | current_scope | |
| The current local scope. | ||
| pm_context_node_t * | current_context | |
| The current parsing context. | ||
| pm_static_literals_t * | current_hash_keys | |
| The hash keys for the hash that is currently being parsed. | ||
| const pm_encoding_t * | encoding | |
| The encoding functions for the current file is attached to the parser as it's parsing so that it can change with a magic comment. | ||
| pm_encoding_changed_callback_t | encoding_changed_callback | |
| When the encoding that is being used to parse the source is changed by prism, we provide the ability here to call out to a user-defined function. | ||
| const uint8_t * | encoding_comment_start | |
| This pointer indicates where a comment must start if it is to be considered an encoding comment. | ||
| pm_lex_callback_t * | lex_callback | |
| This is an optional callback that can be attached to the parser that will be called whenever a new token is lexed by the parser. | ||
| pm_string_t | filepath | |
| This is the path of the file being parsed. | ||
| pm_constant_pool_t | constant_pool | |
| This constant pool keeps all of the constants defined throughout the file so that we can reference them later. | ||
| pm_line_offset_list_t | line_offsets | |
| This is the list of line offsets in the source file. | ||
| pm_node_flags_t | integer_base | |
| We want to add a flag to integer nodes that indicates their base. | ||
| pm_string_t | current_string | |
| This string is used to pass information from the lexer to the parser. | ||
| int32_t | start_line | |
| The line number at the start of the parse. | ||
| const pm_encoding_t * | explicit_encoding | |
| When a string-like expression is being lexed, any byte or escape sequence that resolves to a value whose top bit is set (i.e., >= 0x80) will explicitly set the encoding to the same encoding as the source. | ||
| pm_node_list_t * | current_block_exits | |
| When parsing block exits (e.g., break, next, redo), we need to validate that they are in correct contexts. | ||
| pm_options_version_t | version | |
| The version of prism that we should use to parse. | ||
| uint8_t | command_line | |
| The command line flags given from the options. | ||
| int8_t | frozen_string_literal | |
| Whether or not we have found a frozen_string_literal magic comment with a true or false value. | ||
| bool | parsing_eval | |
| Whether or not we are parsing an eval string. | ||
| bool | partial_script | |
| Whether or not we are parsing a "partial" script, which is a script that will be evaluated in the context of another script, so we should not check jumps (next/break/etc.) for validity. | ||
| bool | command_start | |
| Whether or not we're at the beginning of a command. | ||
| bool | in_endless_def_body | |
| Whether or not we're currently parsing the body of an endless method definition. | ||
| bool | recovering | |
| Whether or not we're currently recovering from a syntax error. | ||
| bool | continuable | |
| Whether or not the source being parsed could become valid if more input were appended. | ||
| bool | encoding_locked | |
| This is very specialized behavior for when you want to parse in a context that does not respect encoding comments. | ||
| bool | encoding_changed | |
| Whether or not the encoding has been changed by a magic comment. | ||
| bool | pattern_matching_newlines | |
| This flag indicates that we are currently parsing a pattern matching expression and impacts that calculation of newlines. | ||
| bool | in_keyword_arg | |
| This flag indicates that we are currently parsing a keyword argument. | ||
| bool | semantic_token_seen | |
| Whether or not the parser has seen a token that has semantic meaning (i.e., a token that is not a comment or whitespace). | ||
| bool | current_regular_expression_ascii_only | |
| True if the current regular expression being lexed contains only ASCII characters. | ||
| bool | warn_mismatched_indentation | |
| By default, Ruby always warns about mismatched indentation. | ||
Detailed Description
This struct represents the overall parser.
It contains a reference to the source file, as well as pointers that indicate where in the source it's currently parsing. It also contains the most recent and current token that it's considering.
Member Function Documentation
◆ pm_parser_init()
| PRISM_EXPORTED_FUNCTION void pm_parser_init | ( | pm_arena_t * | arena, |
| pm_parser_t * | parser, | ||
| const uint8_t * | source, | ||
| size_t | size, | ||
| const pm_options_t * | options | ||
| ) |
Initialize a parser with the given start and end pointers.
The resulting parser must eventually be freed with pm_parser_free(). The arena is caller-owned and must outlive the parser — pm_parser_free() does not free the arena.
- Parameters
-
arena The arena to use for all AST-lifetime allocations. parser The parser to initialize. source The source to parse. size The size of the source. options The optional options to use when parsing. These options must live for the whole lifetime of this parser.
◆ pm_parser_register_encoding_changed_callback()
| PRISM_EXPORTED_FUNCTION void pm_parser_register_encoding_changed_callback | ( | pm_parser_t * | parser, |
| pm_encoding_changed_callback_t | callback | ||
| ) |
Register a callback that will be called whenever prism changes the encoding it is using to parse based on the magic comment.
- Parameters
-
parser The parser to register the callback with. callback The callback to register.
◆ pm_parser_free()
| PRISM_EXPORTED_FUNCTION void pm_parser_free | ( | pm_parser_t * | parser | ) |
Free any memory associated with the given parser.
This does not free the pm_options_t object that was used to initialize the parser.
- Parameters
-
parser The parser to free.
◆ pm_parse()
| PRISM_EXPORTED_FUNCTION pm_node_t * pm_parse | ( | pm_parser_t * | parser | ) |
Initiate the parser with the given parser.
- Parameters
-
parser The parser to use.
- Returns
- The AST representing the source.
◆ pm_parse_stream()
| PRISM_EXPORTED_FUNCTION pm_node_t * pm_parse_stream | ( | pm_arena_t * | arena, |
| pm_parser_t * | parser, | ||
| pm_buffer_t * | buffer, | ||
| void * | stream, | ||
| pm_parse_stream_fgets_t * | stream_fgets, | ||
| pm_parse_stream_feof_t * | stream_feof, | ||
| const pm_options_t * | options | ||
| ) |
Parse a stream of Ruby source and return the tree.
- Parameters
-
arena The arena to use for all AST-lifetime allocations. parser The parser to use. buffer The buffer to use. stream The stream to parse. stream_fgets The function to use to read from the stream. stream_feof The function to use to determine if the stream has hit eof. options The optional options to use when parsing.
- Returns
- The AST representing the source.
Field Documentation
◆ arena
| pm_arena_t* pm_parser::arena |
The arena used for all AST-lifetime allocations.
Caller-owned.
◆ node_id
| uint32_t pm_parser::node_id |
The next node identifier that will be assigned.
This is a unique identifier used to track nodes such that the syntax tree can be dropped but the node can be found through another parse.
◆ next_start
| const uint8_t* pm_parser::next_start |
This is a special field set on the parser when we need the parser to jump to a specific location when lexing the next token, as opposed to just using the end of the previous token.
Normally this is NULL.
◆ heredoc_end
| const uint8_t* pm_parser::heredoc_end |
This field indicates the end of a heredoc whose identifier was found on the current line.
If another heredoc is found on the same line, then this will be moved forward to the end of that heredoc. If no heredocs are found on a line then this is NULL.
◆ data_loc
| pm_location_t pm_parser::data_loc |
An optional location that represents the location of the END marker and the rest of the content of the file.
This content is loaded into the DATA constant when the file being parsed is the main file being executed.
◆ current_hash_keys
| pm_static_literals_t* pm_parser::current_hash_keys |
The hash keys for the hash that is currently being parsed.
This is not usually necessary because it can pass it down the various call chains, but in the event that you're parsing a hash that is being directly pushed into another hash with **, we need to share the hash keys so that we can warn for the nested hash as well.
◆ filepath
| pm_string_t pm_parser::filepath |
This is the path of the file being parsed.
We use the filepath when constructing SourceFileNodes.
◆ integer_base
| pm_node_flags_t pm_parser::integer_base |
We want to add a flag to integer nodes that indicates their base.
We only want to parse these once, but we don't have space on the token itself to communicate this information. So we store it here and pass it through when we find tokens that we need it for.
◆ current_string
| pm_string_t pm_parser::current_string |
This string is used to pass information from the lexer to the parser.
It is particularly necessary because of escape sequences.
◆ start_line
| int32_t pm_parser::start_line |
The line number at the start of the parse.
This will be used to offset the line numbers of all of the locations.
◆ explicit_encoding
| const pm_encoding_t* pm_parser::explicit_encoding |
When a string-like expression is being lexed, any byte or escape sequence that resolves to a value whose top bit is set (i.e., >= 0x80) will explicitly set the encoding to the same encoding as the source.
Alternatively, if a unicode escape sequence is used (e.g., \u{80}) that resolves to a value whose top bit is set, then the encoding will be explicitly set to UTF-8.
The next time this happens, if the encoding that is about to become the explicitly set encoding does not match the previously set explicit encoding, a mixed encoding error will be emitted.
When the expression is finished being lexed, the explicit encoding controls the encoding of the expression. For the most part this means that the expression will either be encoded in the source encoding or UTF-8. This holds for all encodings except US-ASCII. If the source is US-ASCII and an explicit encoding was set that was not UTF-8, then the expression will be encoded as ASCII-8BIT.
Note that if the expression is a list, different elements within the same list can have different encodings, so this will get reset between each element. Furthermore all of this only applies to lists that support interpolation, because otherwise escapes that could change the encoding are ignored.
At first glance, it may make more sense for this to live on the lexer mode, but we need it here to communicate back to the parser for character literals that do not push a new lexer mode.
◆ current_block_exits
| pm_node_list_t* pm_parser::current_block_exits |
When parsing block exits (e.g., break, next, redo), we need to validate that they are in correct contexts.
For the most part we can do this by looking at our parent contexts. However, modifier while and until expressions can change that context to make block exits valid. In these cases, we need to keep track of the block exits and then validate them after the expression has been parsed.
We use a pointer here because we don't want to keep a whole list attached since this will only be used in the context of begin/end expressions.
◆ frozen_string_literal
| int8_t pm_parser::frozen_string_literal |
Whether or not we have found a frozen_string_literal magic comment with a true or false value.
May be:
- PM_OPTIONS_FROZEN_STRING_LITERAL_DISABLED
- PM_OPTIONS_FROZEN_STRING_LITERAL_ENABLED
- PM_OPTIONS_FROZEN_STRING_LITERAL_UNSET
◆ parsing_eval
| bool pm_parser::parsing_eval |
Whether or not we are parsing an eval string.
This impacts whether or not we should evaluate if block exits/yields are valid.
◆ in_endless_def_body
| bool pm_parser::in_endless_def_body |
Whether or not we're currently parsing the body of an endless method definition.
In this context, PM_TOKEN_KEYWORD_DO_BLOCK should not be consumed by commands (it should bubble up to the outer context).
◆ continuable
| bool pm_parser::continuable |
Whether or not the source being parsed could become valid if more input were appended.
This is set to false when the parser encounters a token that is definitively wrong (e.g., a stray end or ]) as opposed to merely incomplete.
◆ encoding_locked
| bool pm_parser::encoding_locked |
This is very specialized behavior for when you want to parse in a context that does not respect encoding comments.
Its main use case is translating into the whitequark/parser AST which re-encodes source files in UTF-8 before they are parsed and ignores encoding comments.
◆ encoding_changed
| bool pm_parser::encoding_changed |
Whether or not the encoding has been changed by a magic comment.
We use this to provide a fast path for the lexer instead of going through the function pointer.
◆ warn_mismatched_indentation
| bool pm_parser::warn_mismatched_indentation |
By default, Ruby always warns about mismatched indentation.
This can be toggled with a magic comment.
The documentation for this struct was generated from the following files: